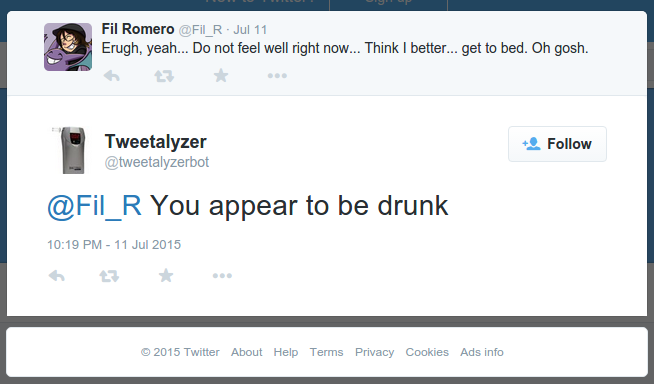
Detecting Drunk Tweets with Deep Learning
The Metamind API, described here by Richard Socher, can be used for some interesting applications, like stock-trading bots. Instead of doing that, I decided to build a Twitter bot that detects drunk tweets.
My original plan was to use Clojure for this project, but the MetaMind API only provides a Python client library, so I decided to compromise and use Hy, a dialect of Lisp that uses Python. This way I can use the MetaMindApi Python library, the Twitter Python library, and still have fun with Clojure-like syntax.
Methodology
The Tweetalyzer bot has two parts - a program that scrapes Twitter and generates labeled training data, and the bot itself that listens to live tweets, classifies them, and responds if they appear to be drunk.
The trick I use to get labeled drunk tweets is to search for tweets containing the phrase “you’re drunk”, or some variation of that. Once I’ve subscribed to this stream of “drunk reply tweets”, I inspect each one for the in_reply_to_status_id attribute to get the original tweet. This gives me a stream of human-labeled drunk tweets. I also sample random tweets from the original stream to use as my baseline non-drunk tweets.
I let this program run over the weekend (enough time to gather several thousand labeled tweets), and then upload the data to MetaMind to generate a drunk tweet prediction model. The trained model allows me to predict in real-time if a new tweet is drunk or sober based only on the text.
I deploy the bot to Heroku, and let the bot run in perpetuity, detecting drunk tweets on the Twitter “sample” stream, and notifying users who post drunk tweets.
Collecting Training Data
I use the track parameter to get the stream of tweets matching my specific criteria. In Hy, this looks like this:
(defn text-filtered-stream [q]
"Make an iterator of text filtered tweets"
(apply (. stream-client.statuses filter) [] {"track" q}))
This was the trickiest thing to figure out in Hy. In order to call a function with keyword arguments, you have to use Hy’s apply function with the kwargs passed as a dict.
I generate the “drunk tweet stream” from the “sample stream” by passing the stream iterator through several map and filter steps using the Hy version of Clojure’s threading macro:
(defn drunk-tweets []
"Get an iterator of human-labeled drunk tweets"
(let [[q (.join "," phrases)]
[fs (t.text-filtered-stream q)]]
(->> fs
(filter t.has-text?)
(filter has-drunk-response-phrase?)
(map get-drunk-tweet)
(filter identity)
(filter t.has-text?)
(filter t.in-english?))))
I can then run the training program and save the outputted TSV training data.
hy tweetalyzer/train.hy > training_data.tsv
and upload the TSV file to Metamind.
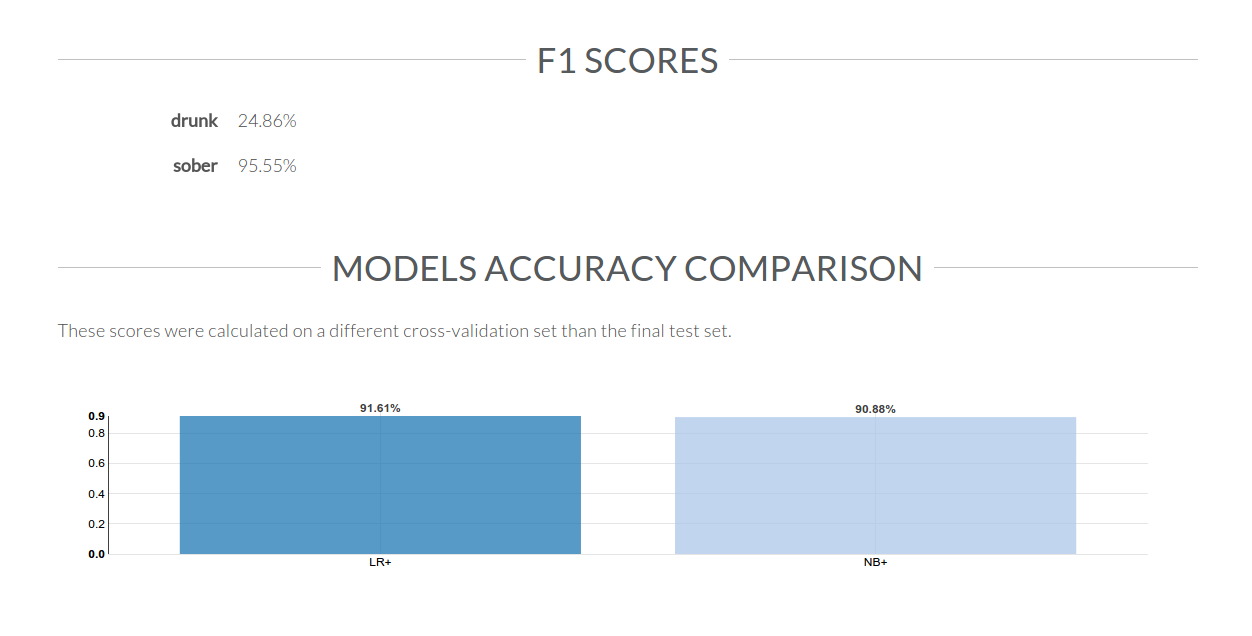
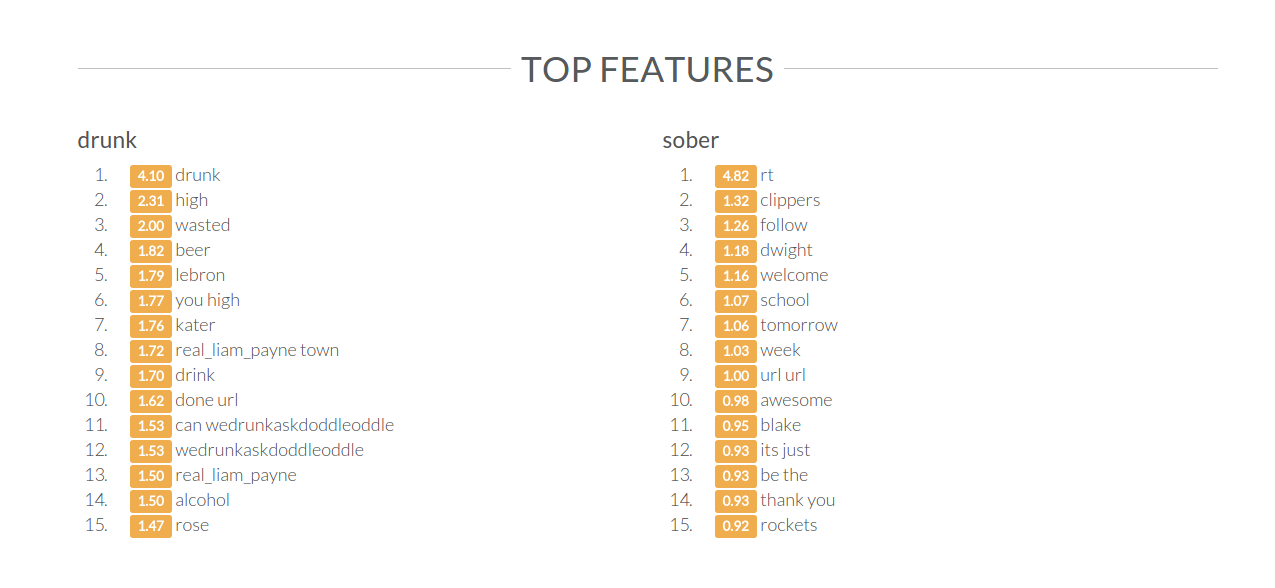
Now I can see some useful statistics and features of the newly-trained classifier model:

Making live predictions
The chat-bot uses the same “sample” stream API to gather live tweets. It checks only the tweets that have text and are in english:
(defn candidate-tweets []
"Get a sample stream of tweets to check"
(->> (t.sample-stream)
(filter t.has-text?)
(filter t.in-english?)))
I then define a predicate function called is-drunk? to determine the drunkness of a given tweet using the predicted label from the Metamind classifier:
(defn is-drunk? [tweet]
"Return True if the tweet is classified as drunk"
(let [[txt (t.tweet_text tweet)]
[prediction (c.predict txt)]]
(= "drunk" prediction)))
At this point, I will introduce the first side-effecting function, the one that will actually send the tweet response when it finds a drunk tweet. I call it tweetalyze:
(defn tweetalyze [tweet]
"Predict if a tweet is a drunk tweet, and if so, reply."
(do (print "Checking tweet: " (t.tweet-attr tweet "id"))
(if (is-drunk? tweet)
(respond tweet))))
Now all that is left is to call the tweetalyze function on every tweet in the candidate stream. But there is a complication. The Metamind API limits users to 1000 classifier predictions per day. So I have to space out the allotted requests evenly over every 24 hour period.
I first define a predicate to tell if the minimum amount of time has passed since the last API request:
(defn ready-for-request? [prev cur]
"Check if enough time passed (for rate limiting)"
(let [[diff (- cur prev)]]
(> diff interval)))
And then I check this predicate for every tweet in the candidate stream:
(defn listen []
"Listen to the tweet stream and check for drunk tweets periodically"
(let [[t (now)]]
(for [tweet (candidate-tweets)]
(if (ready-for-request? t (now))
(do (setv t (now))
(tweetalyze tweet))))))
Deploying
Now I can run the bot locally with the main function, but I want it to run of Heroku indefinitely. So I create a launch.py module and a forman Procfile with a single worker dyno:
import hy
import tweetalyzer.bot
print("Starting bot...")
tweetalyzer.bot.start()
print("Shutting down...")
This worked flawlessy for a few months until the beginning of August, when Heroku changed their pricing policy. Because the bot is deployed on the free tier, it shuts down every day after 16 hours of activity, and restarts the next day.